

🤓 How to Use ChatGPT’s New Project-only Memory
PLUS: This Week in AI

Quick heads up: I’m taking next week off from the newsletter to focus on some client work.
But I’ll be back in your inbox Friday, September 13th. Let’s hope it’s a lucky one.
The more ChatGPT learns about you, the more useful it becomes.
It remembers your background, preferences, writing style, and even your favorite formatting quirks.
But as memory gets more powerful, there’s also more potential for it to carry over things you didn’t intend—from one conversation, client, or project into another.
That’s why OpenAI added a new setting: Project-only memory.
It keeps ChatGPT’s memory contained to a specific project, so the context it picks up doesn’t bleed into or influence anything else you’re working on.
This means ChatGPT will only reference the chats, files, and instructions inside that project without pulling details from:
Previously saved memories
General chat history
Conversations within other projects
And just as importantly, it won’t carry anything from this project into future chats elsewhere.
What Project-only Memory is Useful For
Let’s say you’re a consultant with multiple clients across industries, each with their own priorities, stakeholders and way of working.
Maybe one prefers formal, bullet-point updates, while another wants friendly, conversational copy.
You want ChatGPT to remember the key decision-makers, how each client defines success, and how they prefer to communicate, without any of it crossing over to other conversations.
With project-only memory, ChatGPT picks up that context and keeps it anchored inside the right project.
Or maybe you’re working with a UK-based team and constantly adjusting spelling to match British English (favourite, not favorite), time zones (BST, not PST), and date formatting (day/month/year).
Project-only memory picks up those details as you go, and applies them consistently inside that project, without slipping them back into your U.S. work or personal chats.
How To Use Project-only Memory
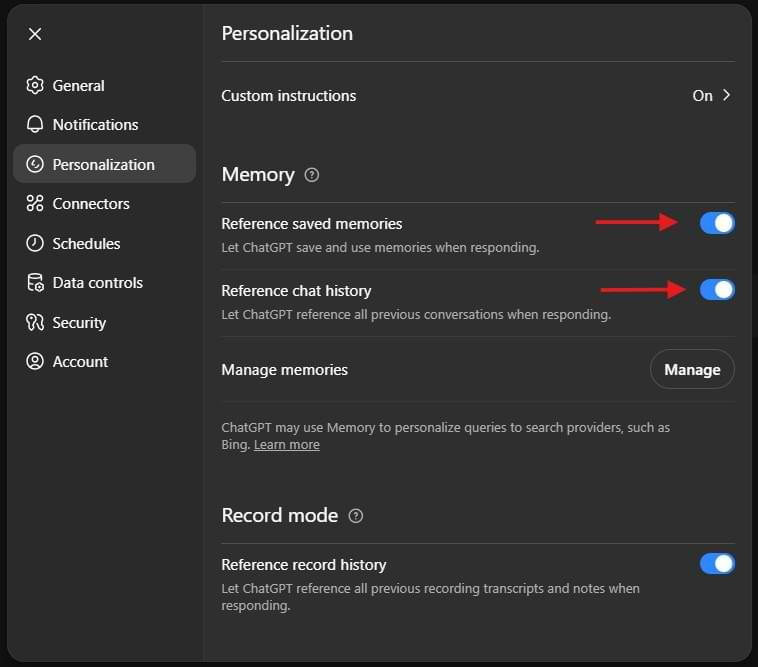
Personalized memory must be enabled to use this feature.
1. Go to Settings → Personalization → Memory → Toggle ON both: “Reference saved memories” and “Reference chat history”
1. Create a new project
2. Click “More options” → Choose Project-only under “Memory”
(Yes, the dropdown looks like plain text. It’s easy to miss.)

A Few Things to Know
Once you set a project to Project-only memory, you can’t change it later.
It only works on new projects— not existing projects (but you can recreate a project with the same name, instructions and files and move your chats into it)
There’s no “memory list” to browse like with “saved memories”, so no way to know exactly what it’s remembering.
Currently available on web only (not mobile)
Only available to paid users (any tier)
What You Need to Know About AI This Week ⚡
Clickable links appear underlined in emails and in orange in the Substack app.
I had to start here, because sometimes AI stories are just plain fun:
ChatGPT helped the owner of a stolen Lamborghini track it down—two years later—by identifying a blurred car in the background of an Instagram post.
Hollywood talent reps are using AI tools like ChatGPT and Grok to argue which actors actually drove attention and moved the needle, especially when streamers like Netflix and Amazon won’t share internal numbers.
That data is now being used as a new kind of bargaining chip in deal and compensation negotiations.
Priyanka Chopra Jonas’ team says she drove 50–60% of the online conversation around Prime Video’s Heads of State, with co-leads John Cena and Idris Elba closer to 20–25% each.
But the math underneath those claims is fuzzy.
The metrics include things like overall volume, headline mentions, and something called “quoting intensity”—a measure of how often her words were cited or lifted in coverage.
If you’re looking at impact metrics, whether it’s for dealmaking, PR, or marketing, it helps to separate three very different things:
Volume → How much conversation was there? mentions, headlines, comments, shares.
Weight → Was the conversation actually about the person (and project), or just happening around them?
Pull → Did that attention lead to behavior—search lift, trailer clicks or streams, repeat views?
If the data doesn’t answer that last part, you’re looking at a headline, not a signal.
Because noise ≠ influence.
And attention isn’t proof of impact.
Claude maker Anthropic made a few big moves this week.
1️⃣ It settled a major copyright lawsuit from authors who accused it of scraping 7 million books to train its AI.
A judge previously ruled training was legal if the books were purchased, but Anthropic was still on the hook for allegedly downloading pirated copies first. The confidential settlement allows the company to avoid massive financial and reputational damages.
2️⃣ It made a big change to its data privacy policy:
Anthropic will now train its models using your conversations, unless you actively opt out.
The next time you log into Claude, you’ll get a pop-up asking for consent. But the design nudges you to accept, and if you’re not careful, you might breeze right past it (see below).

If you don’t see the prompt, go to Settings → Privacy, and make sure the “Help Improve Claude” toggle is turned OFF.
This marks a meaningful shift.
For a long time, “we don’t train on your data” was core to Anthropic’s brand—positioning them as the more ethical, privacy-conscious alternative to OpenAI and Google.
Now, they’re walking that back.
Maybe it was inevitable. Training data is critical to model development, and Claude can’t improve in a vacuum.
And I’m a big fan of Anthropic and their models. I’m rooting for them.
But if you’re going to retreat from the core values that built your brand, you need to do it with more thoughtfulness and care.
If you’ve built your brand on privacy and trust, the choice to hand over data shouldn’t be something users can miss.
3️⃣ It reported that a hacker used its Claude chatbot to power an “unprecedented” cybercrime spree—using AI to write malware, analyze stolen files, and draft ransom demands. Anthropic has added new safeguards but warns this kind of attack is only going to get easier.
Meta couldn’t buy Midjourney, so now it’s licensing its models instead.
The models will power new image and video tools across Instagram, Facebook, Messenger, and future products.
It’s a strategic shortcut: Midjourney gets access to Meta’s massive user base. Meta gets image models that are fast, beloved, and battle-tested (even if they’re also lawsuit magnets).
Zuck’s bet: Better visuals = stickier content = more data to train the next wave of tools.
Amazon is blocking bots from Meta, Google, and other AI firms, cutting off access to rich product data and reviews that power AI recommendations.
That means less referral traffic back to Amazon, but also more control as it builds its own AI shopping tools to own the entire journey, from discovery to checkout.
Amazon’s blockade hints at an AI economy where high-value transaction data is the currency, and no one’s giving it away for free.
Google Gemini’s upgraded image generator allows users to make more precise, multi-step edits while keeping character consistency. You can see some examples here.
Since the new model has Gemini’s world knowledge, you can do stuff like this with it:
Upload a photo and it turns it into a mini guide—labeling landmarks and adding location-specific facts and details.

This got me thinking about all the ways we could use it for film and TV campaigns, especially when the setting plays a starring role.
You could upload a still from a show and use Gemini to:
Identify the filming location
Add real-world references tied to the setting
Auto-generate location-aware explainers that feel editorial
Also, Google Translate now offers Duolingo-style interactive language practice and live translation across 70+ languages.
And with Google Vids, you can now turn photos into 8-second video clips, auto-cut filler words like “um,” add AI avatars to read your script. You also get basic editing for free.
AI voice cloning is already reshaping India’s dubbing industry, letting producers swap a voice actor’s performance with a star’s cloned voice across multiple languages.
It’s being used in major films, often without consent, credit, or fair pay. Work has already dried up for many, and there are no protections in place. Voice artists are organizing, but without laws or collective pressure, there’s little stopping this shift.
Perplexity’s new $5/month Comet Plus subscription—described by the company as similar to Apple News— promises to pay publishers 80% of revenue based on how often their content is read, cited in AI answers, or used by AI agents.
But Perplexity is already facing mounting legal threats, copyright lawsuits, cease-and-desists, and accusations of scraping blocked content—making this as much a reputational defense as a business model.
OpenAI just handed its consumer business to Fidji Simo, the former Instacart CEO, who will oversee ChatGPT and future products while Sam Altman steps back to focus to infrastructure and long-term bets.

In case you missed last week’s edition, you can find it 👇:


That's all for this week.
I’ll see you on Friday the 13th 🤞. Thoughts, feedback and questions are always welcome and much appreciated. Shoot me a note at avi@joinsavvyavi.com.
Stay curious,
Avi
💙💙💙 P.S. A huge thank you to my paid subscribers and those of you who share this newsletter with curious friends and coworkers. It takes me about 20+ hours each week to research, curate, simplify the complex, and write this newsletter. So, your support means the world to me, as it helps me make this process sustainable (almost 😄).